Playing with h5p.
[h5p id=”2″]
[h5p id=”3″]

What follows is a collection of ad hoc ramblings around learning analytics prompted by a combination of Col’s recent post, associated literature arising from ALASI’2018, and “sustainable retention” project that I’m involved with as part of my new job. It’s mainly sensemaking and questions. Intended to help me clarify some thinking and encourage Col’s to think a bit more about his design theory for meso-level practitioners implementing learning analytics.
In the context of learning analytics, Buckingham Shum and McKay (2018) ask the question, “How can an institution innovate for sustainable impact?”.
Buckingham Shum and McKay (2018) make this comment ” to create much more timely feedback loops for tracking the effectiveness of a complex system” which reminds me of this talk talking about complex systems. A talk that emphasises the importance of loops to complex systems.
Col develops the idea of interaction cycles between people, technology and education objects as part of his explanation for the EASI system’s implementation. Are these a type of loop? A loop that seeks to create more timely feedback loops for tracking/responding to the (non/mis)-use of learning analytics?
Is this particular loop a response to helping address what Buckingham Shum and McKay (2018) see as “It also requires a steady focus on the needs of the user community—what the Design-Based Implementation Research (DBIR) community calls the “persistent problems of practice.”?
Buckingham Shum and McKay (2018) identify three organisational models that they see being used to deliver learning analytics and analyse each. The three are:
Expanded examples of this interesting architecture is provided.
I haven’t yet read all of the paper but it appears that what’s missing is what happens in the shadows. Arguably my current institution fits within one of the organisational architectures identified. As I imagine would many contemporary universities (to varying extents). However, the project I’m getting involved with (and was running before I came on the scene) is beyond/different to the institutional organisational architecture.
Perhaps it’s an example of the need for the third institutional architecture But what do you do as a meso-level practitioner when you don’t have that architecture to draw upon and still have to produce? Are there ways to help address the absence of an appropriate architecture?
Regardless of institutional hierarchies perceived mismatches/disagreements arise. The very nature of the hierarchical organisational map (the Buckingham Shum and McKay article includes a number of examples) means that there will be competing perspectives and priorities. Suggesting that it may almost be inevitable that shadow systems – systems avoiding the accepted organisational way – will arise.
I would assume that an effective institutional organisational architecture would reduce this likelihood, but will it remove it?
The project I’m involved with started 6 months ago. It’s a local response to an institutional strategic issue. It was original implemented using Excel, CSV files and various kludges around existing data and technology services.
I’m wondering how much the broader organisation knows about this project and how many other similar projects are happening? Here and elsewhere? Small scale projects implemented with consumer software?
Buckingham Shum and McKay (2018) identify a “chasm between innovation and infrastructure” and talk about three transitions:
This is something I’ve struggled with, it’s the first question – Does institutional learning analytics have an incomplete focus? – in this paper. Does all learning analytics have to scale to mainstream rollout?
Are there ways – including organisational architectures and information technology infrastructures – that enable the development of learning analytics specific to disciplinary and course level contexts? Should there be?
Might a learning analytics platform/framework something like what is mentioned by Buckingham Shum and McKay (2018) ” a shared, extensible framework that can be used by all tools, preventing the need to re-create this framework for each tool” something that might enable this?
The notion of scale and its apparent necessity is something I’ve yet to grok to my satisfaction. Some very smart people like these authors see scale as necesary. The diagram from some ALASI presentation slides in Col’s post includes an arrow for scale. Suggesting that “Innovation and problem solving” must scale to become mainstream.
Perhaps I’m troubled by the interpretation of scale meaning used by lots of people? There are some things that won’t be used by lots of people, but are still useful.
Is the assumption of scale necessary to make it efficient for the organisational systems to provide support? i.e. For any use of digital technology to be supported within an institution (e.g. helpdesk, training etc) it has to be used by a fair number of people. Otherwise it is not cost effective.
Mainstream technology includes other concerns such as security, privacy, responsiveness, risk management etc. However, if as mentioned by Buckingham Shum and McKay (2018) the innovation and problem solving activities are undertaken according to appropriate ” specifications approved by the IT division (e.g., security, architecture), integrating with the institution’s enterprise infrastructure”, then you would hope that those other concerns would be taken care of.
Digital technology is no longer scarce. Meaning the need to be cost efficient and thus used by thousands of people should increasingly not be driven by that expense?
Is it then the design, implementation and maintenance of appropriate solutions using the appropriate institutional infrastructure that is the other major cost? Is this largely driven by the assumption that such activities are costly because they require expertise and can’t be done by just anyone?
But what if learning analytics adopted principles from research into providing computational rich environments for learners. e.g. Grover and Pea’s (2013) principles: low floor, high ceiling, support for the “use-modify-create” progression, scaffolding, enable transfer, support equity, and be systemic and sustainable?
Not that everyone would use it, but enable it so that anyone could.
Col’s post talks about a system he was involved with. A system that succeeded in climbing the three scale transitions mentioned by Buckingham Shum and McKay (2018). It is my understanding that it is soon going to die. Why? Could those reasons be addressed to prevent subsequent projects facing a similar outcome? How does that apply to my current context?
Was it because the system wasn’t built using the approved institutional infrastructure? If so, was the institutional infrastructure appropriate? Institutional infrastructures aren’t known for being flexible and supporting end-user development. Or future proof.
Was it for rational concerns about sustainability, security etc?
Was it because the organisational hierarchy wasn’t right?
The project I’m involved with is attempting the first “scale” transition identified by Buckinham Shum and McKay (2018). The aim is to make this small pilot scalable and low cost. Given the holes in the institutional infrastructure/platform we will be doing some web scraping etc to enable this. The absence of an institutional infrastructure will mean what we do won’t translate to the mainstream.
Should we recognise and embrace this. We’re not trying to scale this, make it mainstream. We’re at the right hand innovation and problem solving end of the image below and aren’t worried about everything to the left. So don’t worry about it.

Grover, S., & Pea, R. (2013). Computational Thinking in K-12: A Review of the State of the Field. Educational Researcher, 42(1), 38–43.
The following is an initial, under-construction attempt to explain (first to myself) how/what role an Information Systems Design Theory (ISDT) places in the research process. Working my way toward a decent explanation for PhD students.
It does this by linking the components of an ISDT with one explanation of a research project. Hopefully connecting the more known concept (research project) with the less known (ISDT). It also uses as an example the ISDT for emergent university e-learning that was developed as part of my PhD thesis.
The following uses Gregor and Jones (2007) specification of a design theory as summarised in the following table adapted from (Gregor & Jones, 2007, p. 322). Reading the expanded descriptions of each of the components of an ISDT in Gregor and Jones (2007) will likely be a useful companion to the following.
| Component | Description |
|---|---|
| Core components | |
| Purpose and scope (the causa finalis) | “What the system is for,” the set of meta-requirements or goals that specifies the type of artifact to which the theory applies and in conjunction also defines the scope, or boundaries, of the theory. |
| Constructs (the causa materialis) | Representations of the entities of interest in the theory. |
| Principle of form and function (the causa formalis) | The abstract “blueprint” or architecture that describes an IS artifact, either product or method/intervention. |
| Artifact mutability | The changes in state of the artifact anticipated in the theory, that is, what degree of artifact change is encompassed by the theory. |
| Testable propositions | Truth statements about the design theory. |
| Justificatory knowledge | The underlying knowledge or theory from the natural or social or design sciences that gives a basis and explanation for the design (kernel theories). |
| Additional components | |
| Principles of implementation (the causa efficiens) | A description of processes for implementing the theory (either product or method) in specific contexts. |
| Expository instantiation | A physical implementation of the artifact that can assist in representing the theory both as an expository device and for purposes of testing. |
This explanation assumes that all research starts with a problem and a question. It’s important (as for all research) that the problem/question be interesting and important. The book “Craft of research” talks about identifying your research question.

An ISDT is generated through design-based research (DBR), which for me at least that it tends to deal with “how” research questions. For example, the research question from my thesis
How to design, implement and support an information system that effectively and efficiently supports e-learning within an institution of higher education?
The challenge here is to develop some knowledge that helps answer this type of question. Baker (2014) talks a bit more about research questions in DBR.
Hopefully the question driving my thesis research is clear from the above. The thesis includes additional background to establish that the related problem (developing IS for e-learning in higher ed) is an important one worthy of research)
DBR aims to help someone do something. The aim of an ISDT is to provide guidance to someone to build an information system that solves an identified problem. But you’re not interested in the technology?
Avison and Eliot (2006) suggests that in comparison to other IT-related disciplines (e.g. computer science, computer science engineering) the information systems discipline is focused more on the focuses on the application of technology and the subsequent interactions between people/organisations (soft issues) and the technology. It’s not just focused on the technologies. They include the following quote from Lee’s (2001) editorial in MISQ
that research in the information systems field examines more than just the technological system, or just the social system, or even the two side by side; in addition, it investigates the phenomena that emerge when the two interact…the emergent soci-technical phenomena
By answering the research question, you’re hoping that people can develop an information system.

The problem with the last image is that it’s a bit like what a consultant does. Someone has a problem, you come in and create something that solves their problem. DBR is not consultancy. It aims to develop generalised knowledge that can inform the development multiple different information systems. Different people in different contexts should be able to develop information systems appropriate to their requirements.

What’s missing in the last diagram is the knowledge that people will use to develop any information system. This knowledge is the answer to the research question/problem that you aim to develop. This is where the ISDT enters the picture. It is a representation of that knowledge that people use to develop an appropriate information system.
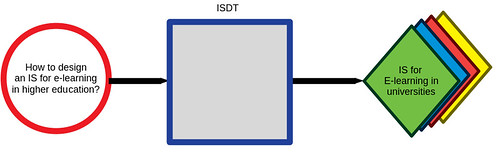
The ISDT encapsulates knowledge about how to build a particular type of information system that effectively answers the research question/problem. i.e. it encapsulates knowledge that serves a particular purpose and scope
But an ISDT is not just a black/grey box. It has components as outlined in the table above.
Johanson and Hasselbring (2018) argue that one of the problems with computer scientists and software engineers is that they wished to focus on general principles at the cost of specific principles. Hence such folk develop artifacts like the software development life cycle (and lots more) that are deemed to be general ways to develop information systems. See Vessey (1997) for more on this, including the lovely quote from Plauger (1993)
If you believe that one size fits all, you are living in a panty-hose commercial
Assuming that your research question/problem is not terribly generic, it should be possible for you to identify the purpose and scope for your ISDT. For example, here’s the summary of the purpose and scope from my ISDT for emergent university e-learning
- Provide ICT functionality to support learning and teaching within a university environment (e-learning).
- Seek to provide context specific functionality that is more likely to be adopted and integrated into everyday practice for staff and students.
- Encourage and enable learning about how e-learning is used. Support and subsequently evolve the system based on that learning.
Your research started with a problem (turned into a question). That problem should have defined something important for someone. Something important that your ISDT is going to provide the knowledge they need to solve by building an information system. i.e. something that is not just hardware and software, but considers those elements, the associated soft issues and the interactions between them.
Your ISDT – in the form of purpose and scope – overlaps/connects with your research question/problem

But as illustrated by the example research question and purpose and scope used here they are different. My original research question is fairly generic. The purpose and scope has a fair bit more detail. Where did that detail come from?
An ISDT should include justificatory knowledge. Knowledge and theory from the natural, social or design sciences that inform how you understand and respond to the research problem. The example purpose and scope in the previous section includes explicit mention of ‘context specific functionality’ and ‘integrated into everyday practice’ (amongst others). Each of these narrow the specific purpose and scope. This ISDT is not just about developing a system that will support L&T in a tertiary setting. It’s also quite explicit that the system should also encourage adoption and evolution.
This particular narrowing is informed by a variety of theoretical insights that form part of the justificatory knowledge of my ISDT. Theoretical insights drawn from end-user development and distributed cognition. One of the reasons why my ISDT is for emergent university e-learning.
This gives some insight into how a different ISDT for university e-learning could take a different approach (informed by different justificatory knowledge). e.g. I’d argue that current approaches to university e-learning tacitly have the purpose (perhaps priority) of being efficient and achieving institutional goals, rather than encouraging adoption, contextual functionality, and emergence.
Design research aims to make use of existing knowledge and theory to construct artefacts that improve some situation (Simon, 1996). How you understand the “some situation” should be informed by your justificatory knowledge.

You want your ISDT to help people design effective/appopriate information systems. But how do people know what to do to develop a good information system? Where’s that knowledge in the ISDT to help them do this?
This is where the design principles enter the picture. There are two sets of design principles:
i.e. what are you going to build? What features does it have?
i.e. how should you build it? What steps should you follow to efficiently and effectively put the IS in place?
These principles should be abstract enough that they can inform the design of different information systems. They should also be directly connected to your ISDT’s justificatory knowledge. You don’t just pull them out of the air, or because that’s they way you do it.

For the emergent university e-learning ISDT there were 13 principles of form and function organised into three groups with explicitly links to justificatory knowledge
And there were 11 principles of implementation organised into another 3 groups, again, each explicitly linked to justificatory knowledge
The premise of an ISDT is that if someone is able to successful follow the design principles then they should be able to expect that they will develop an IS that solves the particular problem in a way that is better in some way than other systems.
If people follow these principles, based on your justificatory knowledge you are claiming that certain things will happen. These are the testable propositions
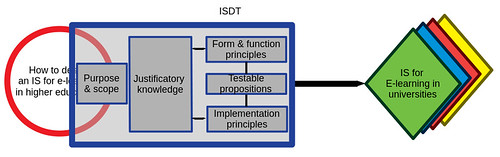
The ISDT for emergent university e-learning has five testable propositions
Each of these are based in some way on justificatory knowledge as instantiated by the design principles.
The first testable proposition is essentially that the resulting IS will be fit for purpose/address the necessary requirements. The remaining propositions identify how the resulting IS will be better than others. Propositions that can be tested once such an IS is instantiated.
Just because you can develop a theory, doesn’t mean it will work. However, if you have a working version of an information system designed using the ISDT (i.e. an instantiation of the ISDT) then it becomes a bit easier to understand. An instantiation also helps identify issues with the ISDT which can be refined (more on this below). An instantiation can also help explain the ISDT.
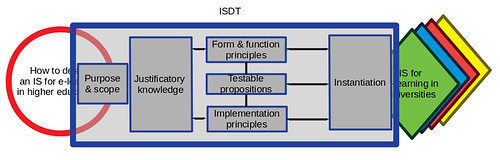
In the above the arrows between instantiation, the design principles, and the testable propositions are intended to indicate how the instantiation should be informed/predicted by the principles and propositions, but also how the experience of building and using the instantiation can influence the principles (more of this below) and propositions.
In spite of the argument above, not everyone assumes that an instantiation is necessary (it’s listed as an additional components in the ISDT specification). As the previous paragraphs suggest I think an instantiation is a necessary component.
The emergent university e-learning ISDT was based on a system called Webfuse used at a particular University from 1996 through 2010 (or so).
The research problem (and scope) and the justificatory knowledge all embody a particular perspective on the world. Rather than trying to understand everything about and every perspective on the research problem (beyond the scope of mere mortals) an ISDT focuses attention on a particular view of the research problem. There are certain elements that are deemed to be more important and more interesting to a particular ISDT than others. These more interesting elements become the constructs of the ISDT. They define the meaning of these interesting elements. They become some of the fundamental building blocks of the ISDT.
The following image perhaps doesn’t capture the importance of constructs.
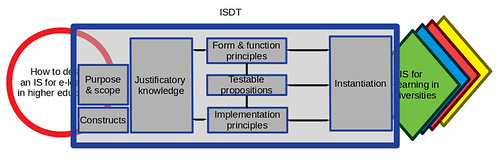
The following table summarises the constructs from the ISDT for emergent university e-learning
| Construct | Definition |
|---|---|
| e-learning | The use of information and communications technologto support and enhance learning and teaching in higher education institutions (OECD, 2005c) |
| Service | An e-learning related function or application such as a discussion forum, chat room, online quiz etc. |
| Package | Mechanism through which all services are integrated into and managed within the system. |
| Conglomerations | Groupings of services that provide scaffolding and context-specific support for the performance of high-level e-learning tasks. (e.g., creating a course site with a specific design; using a discussion forum to host debate; using blogs to encourage reflection) |
Lee’s (2001) quote above mentioned “emergent soci-technical phenomena”. The idea that when technology meets society something different emerges and keeps on emerging. Not just because of the combination of these two complex categories of interest, but also because digital technology itself is protean/mutable. While digital technologies show rapid change due to the evolution of the technology, digital technologies are also inherently protean. They can be programmed.
The importance of this feature means that artifact mutability – how you expect IS built following your ISDT will/should/could change – is a core component of an ISDT.
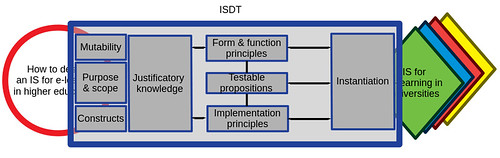
As an ISDT for emergent e-learning artifact mutability/what happens next was a key consideration described as
As an ISDT for emergent e-learning systems the ability to learn and evolve in response to system use is a key part of the purpose of this ISDT. It is actively supported by the principles of form and function, as well as the principles of implementation.
i.e. mutability was a first order consideration in this ISDT. It actively tried to encourage and enable this in a positive way through both sets of principles.
The above has tried to explain the components of an ISDT by starting with a typical research question/problem. It doesn’t address the difficult question of how “how do you formulate an ISDT?”. In particular, how do you do it with some rigor, practical relevance etc. Answering these questions are somewhat independent from the components of an ISDT. Whatever research approach you use should produce appropriately the various components, but how you develop it is separate from the ISDT.
My thesis work followed the iterative action research process from Markus et al (2002)
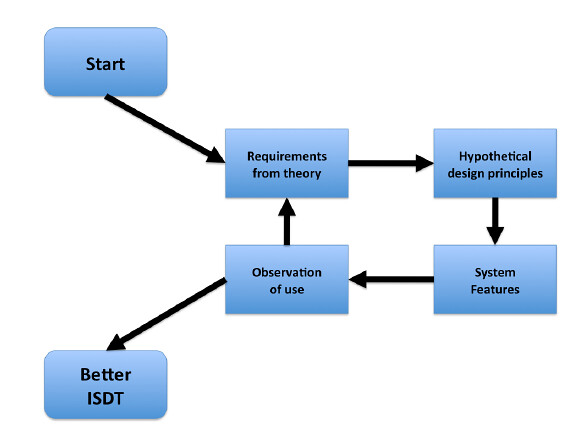
A related but more common research process within design-based research out of the education discipline is Reeves (2006) approach. I’ll expand upon this one, but there are overlaps.
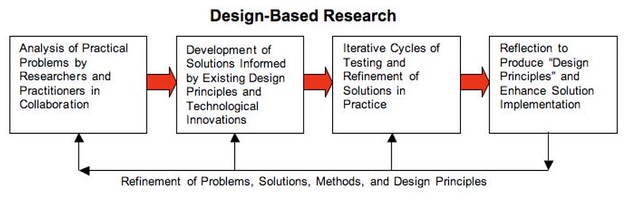
As Reeve’s image sugestions, these aren’t four distinct, sequential phases. Instead, they can tend toward almost to concurrent tasks that you are stepping back and forth between. As you engage in iterative cycles of testing and refinement (3rd phase) you learn something that modifies understanding of the practical problem (1st) and perhaps principles (2nd) and perhaps highlights something to reflect.
However, at least initially, I’m wondering if you should have spent some time developing an initial version of your ISDT (and all its components) fairly early on in the research cycle. This forms the foundation/mechanism by which you move backward and forward between the different stages.
i.e. as you develop a specific solution (instantiation) of your ISDT you might find yourself having to undertake a particular step or develop a particular feature that isn’t explained by your existing design principles.

Similarly, you might be observing an instantiation in action by gathering/analysing data etc (Phase 3) or perhaps you might be reflecting upon what’s happened and realise that a particular issue isn’t covered, or that your initial assumptions were wrong. Leading to more refinement.
That refinement may in turn lead to changes in the instantiation(s) and thus more opportunities to learn and refine.
Avison, D., & Eliot, S. (2006). Scoping the discipline of information systems. In J. L. King & K. Lyytinen (Eds.), Information systems: the state of the field (pp. 3–18). Chichester, UK: John Wiley & Sons.
Bakker, A. (2014). Research Questions in Design-Based Research (pp. 1–6). Retrieved from http://www.fi.uu.nl/en/summerschool/docs2014/design_research_michiel/Research Questions in DesignBasedResearch2014-08-26.pdf
Gregor, S., & Jones, D. (2007). The anatomy of a design theory. Journal of the Association for Information Systems, 8(5), 312–335.
Johanson, A., & Hasselbrin<, W. (2018). Software Engineering for Computational Science: Past, Present, Future. Computing in Science & Engineering. https://doi.org/10.1109/MCSE.2018.108162940
Markus, M. L., Majchrzak, A., & Gasser, L. (2002). A design theory for systems that support emergent knowledge processes. MIS Quarterly, 26(3), 179–212.
Reeves, T. (2006). Design research from a technology perspective. In J. van den Akker, K. Gravemeijer, S. McKenney, & N. Nieveen (Eds.), Educational Design Research (pp. 52–66). Milton Park, UK: Routledge.
Simon, H. (1996). The sciences of the artificial (3rd ed.). MIT Press.
Vessey, I. (1997). Problems Versus Solutions: The Role of the Application Domain in Software. In Papers Presented at the Seventh Workshop on Empirical Studies of Programmers (pp. 233–240). New York, NY, USA: ACM. https://doi.org/10.1145/266399.266419
In the absence of an established workflow for curating thoughts and resources I am using this blog post to save links to some resources. It’s also being used as an initial attempt to write down some thoughts on these resources and beyond. All very rough.
This from the world economic forum (authored by Klaus Schwab, ahh, who is author of two books on shaping the fourth industrial revolution) aims to explain “The Fourth Industrial Revolution: what it means, how to respond”. If offers the following description of the “generations” of revolution
The First Industrial Revolution used water and steam power to mechanize production. The Second used electric power to create mass production. The Third used electronics and information technology to automate production. Now a Fourth Industrial Revolution is building on the Third, the digital revolution that has been occurring since the middle of the last century. It is characterized by a fusion of technologies that is blurring the lines between the physical, digital, and biological spheres.
Immediate reaction to that is that the 3rd revolution – with its focus on electronics and information technology – missed a trick with digital technology. It didn’t understand and leverage the nature of digital technologies sufficiently. In part, this was due to the limited nature of the available digital technology, but also perhaps due to the failure of a connection between the folk who really knew this and the folk trying to do stuff with digital technology.
The WEF post argues that “velocity, scope and systems impact” are why this fourth generation is distinct from the third. They could be right, but again I wonder if ignorance of the nature of digital technology might be a factor?
The WEF argues about the rapid pace of change and how everything is being disrupted. Which brings to mind arguments from Audrey Watters (and I assume others) about how, actually, it’s not all that rapid.
It identifies the possibility/likelihood of inequality. Proposes that the largest benefits of this new revolution (as with others?) accrues to the “providers of intellectual and physical capital – the innovators, shareholders and investors”.
Points to disquiet caused by social media and says more than 30% of the population accesses social media. However, the current social media is largely flawed and ill-designed, it can be done better.
Question: does an understanding of the nature of digital technology help (or is it even required) for that notion of “better”? Can’t be an explanation for all of it, but some? Perhaps the idea is not that you need only to truly know the nature of digital technology, or know only the details of the better learning, business, etc you want to create. You need to know both (with a healthy critical perspective) and be able to fruitfully combine.
Overall, much of this appears to be standard Harvard MBA/Business school like.
The platform economy – technology-enabled platforms – get a mention which also gets a mention in the nascent nature of digital technology stuff I worked on a couple of years ago. Platforms are something the critical perspective has examined, so I wonder if this belongs in the NoDT stuff?
I came to this idea from this post from a principal come consultant/researcher around leading in schools. It’s a post that references this on building the perfect 21st Century worker as apparently captured in the following infographic.
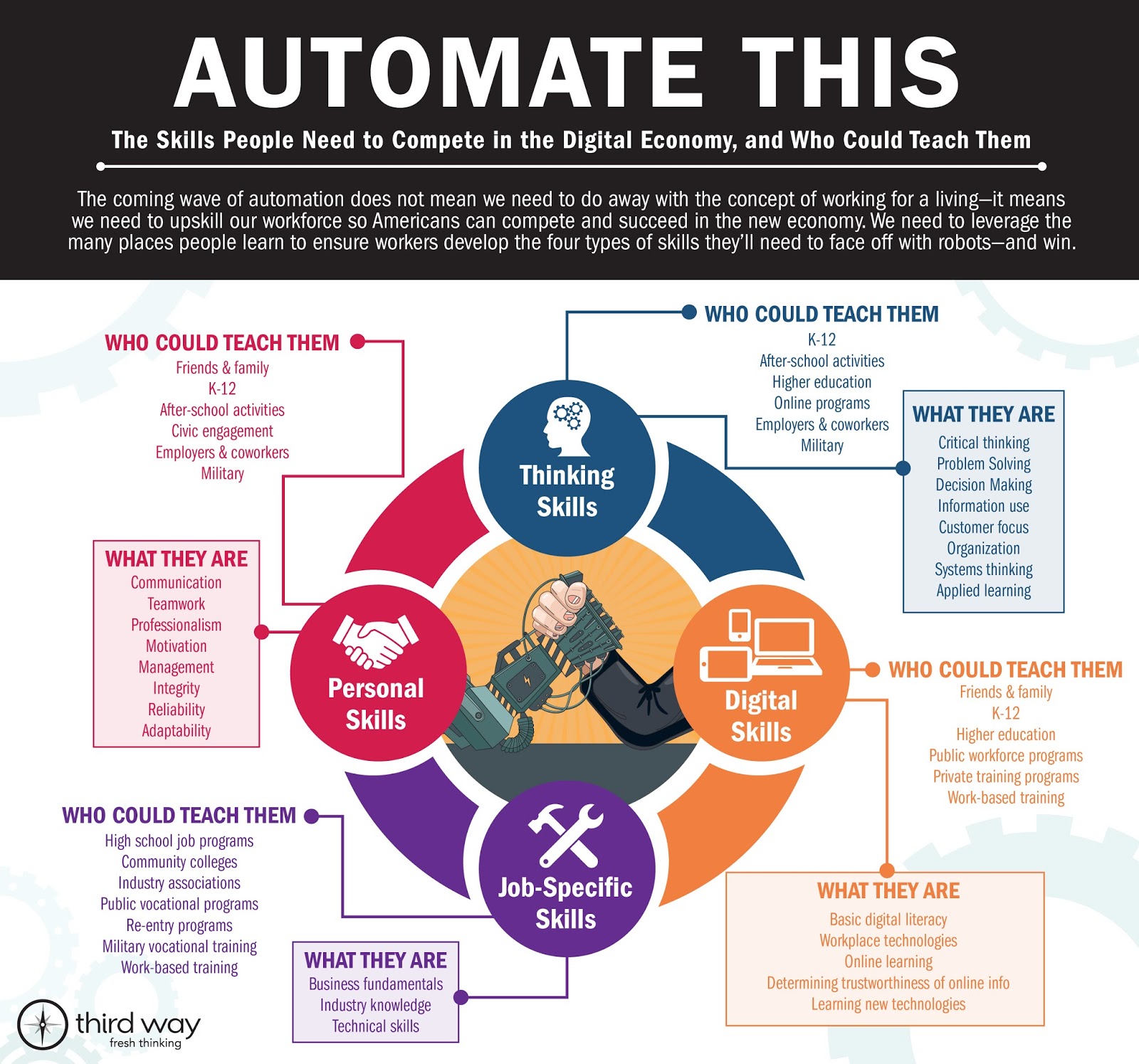
Which includes the obligatory Digital skills which are listed in article as (emphasis added)
- Basic digital literacy – ability to use computers and Internet for common tasks, like emailing
- Workplace technology – using technologies required by the job
- Digital learning – using software or online tools to learn new skills or information
- Confidence and facility learning and using new technologies
- Determining trustworthiness of online information
Talk about setting the bar low and providing a horrendous example of digital literacy, but then it does tend to capture the standard nature of most attempts at digital literacy I’ve seen, including:
(Not to mention that the article uses an image to display the bulleted list above, not text)
Following is a summary of Johanson and Hasselbring (2018) and an exploration of what, if anything, it might suggest for learning design and learning analytics. Johanson and Hasselbring (2018) explore why scientists whom have been developing software to do science (computational science) haven’t been using principles and practices from software engineering to develop this software. The idea is that such an understanding will help frame advice for how computational science can be improved through application of appropriate software engineering practice (**assumption**).
This is interesting because of potential similarities between learning analytics (and perhaps even learning design in our now digitally rich learning environments) and computational science. Subsequently, lessons about if and how computational science has/hasn’t been using software engineering principles might provide useful insights for the implementation of learning analytics and the support of learning design. I’m especially interested due to my observation that both practice and research around learning analytics implementation isn’t necessarily exploring all of the possibilities.
In particular, Johanson and Hasselbring (2018) argue that it is necessary to examine the nature of computational science and subsequently select and adapt software engineering techniques that are better suited to the needs of computational scientists. For me, this generates questions such as:
Increasingly it is seen as necessary that learning analytics be tightly aligned with learning design. Is the nature/outcome/practice of this combination different? Does it require different types of support?
The development of software with which to do science is increasing, but this practice isn’t using software engineering practices. Why? What are the underlying causes? How can it be changed?
Survey of relevant literature examining software development in computational science. About 50 publications examined. A majority case studies, but some surveys.
Identify 13 key characteristics (divided into 3 groups) of computational science that should be considered (see table below) when thinking about which software engineering knowledge might apply and be adapted.
Examines some examples of how software engineering principles might be/are being adapted.
Johanson and Hasselbring (2018) argue that the chasm between computational scientists and software engineering researchers arose from the rush on the part of computer scientists and then software engineers to avoid the “stigma of all things applied”. The search for general principles that applied in all places. Leading to this problem
Because of this ideal of generality, the question of how specifically computational scientists should develop their software in a well-engineered way, would probably have perplexed a software engineer and the answer might have been: “Well, just like any other application software.
In learning analytics there are people offering more LA specific advice. For example, Wise & Vytasek (2017) and just this morning via Twitter this pre-print of looming BJET article. Both focused on providing advice that links learning analytics and learning design.
But I wonder if this is the only way to look at learning analytics? What about learning analytics for reflection and exploration? Does the learning design perspective cover it?
But perhaps a more interesting question might be whether or not it is assumed that the learning analytics/learning design principles identified by these authors should then be implemented using traditional software engineering practices?
|
Category |
Characteristics |
|---|---|
|
Nature of scientific challenges |
Verification and validation is difficult and verification validation Validation is hard Problems arise from four Model of reality is Algorithm used to Implementation of the Combination of models can Testing methods could help, Overly formal software processes restrict research Easterbrook and Johns (2009) big up front design “poor there is a need for the flexibility to quickly Use a very iterative process, iterating over both the Explicit connections with agile software development Representation shown in figure |
|
Limitations of computers |
scientific software not limited by the science theory, but by the available computing resources Some communities moving Intermingling of domain logica and implementation Conflicting software quality requirements interviews of scientific Functional correctness Performance Portability Maintainability |
|
Cultural environment |
Few scientists are trained in software engineering Segal (2007) describe them “In contrast to most But keeping up with sw eng Didn’t want to delegate Different terminology e.g. computational Scientific software in itself has no value but still Code is valued because of Creating a shared understanding of a “code” is preference for informal, “scientists find it Little code re-use Disregard of most modern software engineering methods |
Johanson and Hasselbring (2018) include the following figure as a representation of how scientific software is developed. They note its connections with agile software development, but also describe how computational scientists find even the light weight discipline of agile software development as not a good fit.
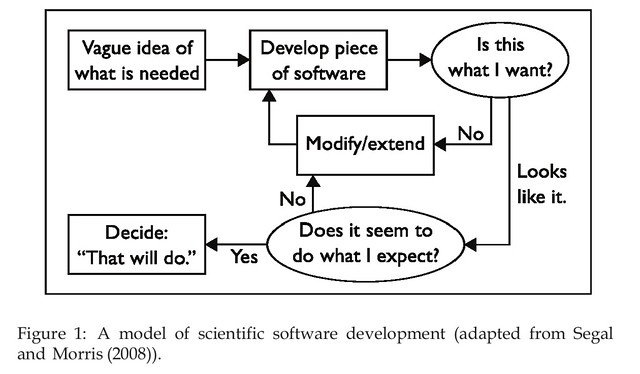
Anecdotally, I’d suggest that the above representation would offer a good description of much of the “learning design” undertaken in universities. Though with some replacements (e.g. “develop piece of software” replaced with “develop learning resource/experience/event”).
If this is the case, then how well does the software engineering approach to the development and implementation of learning analytics (whether it follows the old SDLC or agile practices) fit with this nature of learning design?
Johanson, A., & Hasselbring, W. (2018). Software Engineering for Computational Science: Past, Present, Future. Computing in Science & Engineering. https://doi.org/10.1109/MCSE.2018.108162940
Wise, A., & Vytasek, J. (2017). Learning Analytics Implementation Design. In C. Lang, G. Siemens, A. F. Wise, & D. Gaševic (Eds.), The Handbook of Learning Analytics (1st ed., pp. 151–160). Alberta, Canada: Society for Learning Analytics Research (SoLAR). Retrieved from http://solaresearch.org/hla-17/hla17-chapter1
@OpenKuroko is lucky enough to be attending OER18, which got off with a bang on Twitter last night. This brief bit of thinking out loud explores the differences in understanding of the word repository by two different, but related communities, open source software and Open Educational Resources. It’s sparked by a combination of some recent work that has me returning to my open source software use/development origins and this tweet from @OpenKuroko. The tweet reports a comment from #OER18
there are plenty of #OER repositories, but no one outside academia knows about them’
Based on the following, perhaps there are some lessons to be learned by the OER/OEP movement from the open source software community about how to re-conceptualise and redesign repositories so that they are actually not only known about, but actually actively used. One lesson appears to stop thinking about the repository as a place to store and share resources, but reframe it as an environment to help a community engage in relevant open (educational) practices. At some level it echoes the “A way forward” section in Albion, Jones, Jones and Campbell (2017)
Open Source software development is often cited as an inspiration for the OER movement. If you mention the term repository to anyone currently somewhat connected to using or developing open source software than their immediate association is almost certainly going to be of a GitHub repository, defined in that intro tutorial as “usually used to organise a single project”. i.e. a GitHub repository enables and encourages just about anyone who wants to, to engage in a range of OEP around software development.
GitHub is based on Git. An open source tool for version control. Version control is a standard practice for software developers. Git was designed by an expert (open source) software developer (Linus Torvalds, creator of Linux) to be used by an open source project (Linux). It was designed to solve a number of known problems with existing tools. Git was then used by GitHub to provide a hosting service for version control. GitHub added features to support this task to make it even easier for people to engage in open (and not open if they paid) software development. As explained on the Wikipedia page for GitHub, GitHub provided additional support for standard tasks such as “bug tracking, feature requests, task management, and wikis”.
This combination was so successful that Wikipedia cites sources that have GitHub hosting 57,000,000 repositories being used by almost 20,000,000 people. In the Open Source software community, people know about and tend to use git and GitHub. If you’ve looked at a recent computing technical book then chances are that book has a GitHub repository that hosts the support code for the book and provides an environment where readers can ask questions and share problems.
Echoing the #OER18 comment, but does anyone outside of open source software development know about Git and GitHub repositories?
There are signs. If you’re a researcher doing work in Data Science with R or perhaps Python. Then chances are you are using GitHub to share your code and work toward reproducibility of research. The idea of using GitHub to host course material is increasingly used by computer science educators, but is also spreading further.
But it’s not all techno-optimism. This blog post from Dan Meyer is titled “Why Secondary Teachers Don’t Want a GitHub for Lesson Plans” and outlines a range of reasons why. Many of these reasons will echo with reasons heard by folk involved with OER.
While there may be some value in other communities (e.g. open educators) using GitHub, perhaps the bigger point is not that they should use Github. Git and GitHub provide repositories for software development. Git and Github were designed and developed by software developers to make the practice of software development (open or not) more effective. More interesting questions might be
The following is really just taking some notes for future use. Related to the idea that attempts to improve learning and teaching within Universities needs to think about more than just workshops, manuals etc. The idea being that the aim isn’t to improve the knowledge of learning and teaching of University teachers, it’s to help change and improve what they do. Something I’ve vaguely written about ages ago (though I don’t necessarily agree with all of that).
Allen et al (2002) cite Kilvington & Allen (2001)
Behaviour change = Knowing what to do + Enabling environment + Imperative
A nice simplistic representation that resonates, but is likely limited.
Later Allen et al (2002) offer
Social Network Theory (Verity 2002) is a framework that looks at social behaviour through
behaviour change, it is necessary to develop a supportive, or enabling, environment. One major aspect of developing a supportive environment is about creating links between people, which allow information and learning to occur across social networks. The creation of these links is referred to in development literature as ‘social capital’ (p. 21)
and then
Studies into behaviour change have highlighted the following aspects:
- Behaviour change is different for every person, and does not occur in one step.
People move through stages of change in their own ways and in their own time.- The enabling environment influences these stages of change.
- People adapt and improve the enabling environment through individual and
collective capacity development.- The crucial goal for any programme, then, is to enhance people’s capacity to
modify their environment so that it enables movement through stages of change.(p. 24)
This resonates on a few possible levels
Allen, W., Kilvington, M., & Horn, C. (2002). Using Participatory and Learning-Based Approaches for Environmental Management to Help Achieve Constructive Behaviour Change (Landcare Research Contract Report No. LC0102/057). Wellington, NZ: New Zealand Ministry for the Environment. Retrieved from http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.199.6053&rep=rep1&type=pdf
David Jones, Celeste Lawson, Colin Beer, Hazel Jones
Paper accepted to the LAK2018 workshop – Participatory design of learning analytics
Jones, D., Lawson, C., Beer, C., & Jones, H. (2018). Context-Appropriate Scaffolding Assemblages: A generative learning analytics platform for end-user development and participatory design. In A. Pardo, K. Bartimote, G. Lynch, S. Buckingham Shum, R. Ferguson, A. Merceron, & X. Ochoa (Eds.), Companion Proceedings of the 8th International Conference on Learning Analytics and Knowledge. Sydney, Australia: Society for Learning Analytics Research. Retrieved from http://bit.ly/lak18-companion-proceedings
There remains a significant tension in the development and use of learning analytics between course/unit or learning design specific models and generic, one-size fits all models. As learning analytics increases its focus on scalability there is a danger of erring toward the generic and limiting the ability to align learning analytics with the specific needs and expectations of users. This paper describes the origins, rationale, and use cases of a work in progress design-based research project attempting to develop a generative learning analytics platform. Such a platform encourages a broad audience to develop unfiltered and unanticipated changes to learning analytics. It is hoped that such a generative platform will enable the development and greater adoption of embedded and contextually specific learning analytics and subsequently improve learning and teaching. The paper questions which tools, social structures, and techniques from participatory design might inform the design and use of the platform, and asks whether or not participatory design might be more effective when partnered with generative technology?
Keywords: Contextually Appropriate Scaffolding Assemblages (CASA); generative platform; participatory design; DIY learning analytics
One size does not fit all in learning analytics. There is no technological solution that will work for every teacher, every time (Mishra & Koehler, 2006). Context specific models improve teaching and learning, yield better results and improve the effectiveness of human action (Baker, 2016; Gašević, Dawson, Rogers, & Gasevic, 2016). Despite this, higher education institutions tend to adopt generalised approaches to learning analytics. Whilst this may be cost effective and efficient for the organisation (Gašević et al., 2016), the result is a generic approach that provides an inability to cater for the full diversity of learning and learners and shows “less variety than a low-end fast-food restaurant” (Dede, 2008).
Institutional implementation of learning analytics in terms of both practice and research remain limited to conceptual understandings and are empirically narrow or limited (Colvin, Dawson, Wade, & Gašević, 2017). In practice, learning analytics has suffered from a lack of human-centeredness (Liu, Bartimote-Aufflick, Pardo, & Bridgeman, 2017). Even when learning analytics tools are designed with the user in mind (e.g. Corrin et al., 2015), the resulting tools tend to be what Zittrain (2008) defines as non-generative or sterile. In particular, the adoption of such tools tends to require institutional support and subsequently leans toward the generic, rather than the specific. This perhaps provides at least part of the answer of why learning analytics dashboards are seldom used to intervene during the teaching of a course (Schmitz, Limbeek, van Greller, Sloep, & Drachsler, 2017) and leading us to the research question: How can the development of learning analytics better support the needs of specific contexts, drive adoption, and ongoing design and development? More broadly, we are interested in if and how learning analytics can encourage the adoption of practices that position teaching as design and subsequently improve learning experiences and outcomes (Goodyear, 2015) by supporting a greater focus on the do-it-with (DIW – participatory design) and do-it-yourself (DIY) design (where teachers are seen as designers), implementation, and application of learning analytics. This focus challenges the currently more common Do-It-To (DIT) and Do-It-For (DIF) approaches (Beer, Tickner & Jones, 2014).
This project seeks to explore learning analytics using a design-based research approach informed by a broader information systems design theory for e-learning (Jones, 2011), experience with Do-It-With (DIW) (Beer et al., 2014) and teacher Do-It-Yourself (DIY) learning analytics (Jones, Jones, Beer, & Lawson, 2017), and technologies associated with reproducible research to design and test a generative learning analytics platform. Zittrain (2008) defines a generative system as having the “capacity to produce unanticipated change through unfiltered contributions from broad and varied audiences” (p. 70). How generative a system is depends on five principal factors: (1) leverage; (2) adaptation; (3) ease of mastery; (4) accessibility; and (5) transferability (Zittrain, 2008). A focus for this project is in exploring how and if a generative learning analytics platform can act as a boundary object for the diverse stakeholders involved with the design, implementation and use of institutional learning analytics (Suthers & Verbert, 2013). Such an object broadens the range of people who can engage in creative acts of making learning analytics as a way to make sense of current and future learning and teaching practices and the contexts within which it occurs. The platform – named CASA, an acronym standing for Contextually Appropriate Scaffolding Assemblages – will be designed to enable all stakeholders alone or together to participate in decisions around the design, development, adoption and sharing of learning analytics tools. These tools will be created by combining, customising, and packaging existing analytics – either through participatory design (DIW) or end-user development (DIY) – to provide context-sensitive scaffolds that can be embedded within specific online learning environments.
Jones et al., (2017) uses a case of teacher DIY learning analytics to draw a set of questions and implications for the institutional implementation of learning analytics and the need for CASA. The spark for the teacher DIY learning analytics was the observation that it took more than 10 minutes, using two separate information systems including a number of poorly designed reports, to gather the information necessary to respond to an individual learner’s query in a discussion forum. The teacher was able to design an embedded, ubiquitous and contextually specific learning analytics tool (Know Thy Student) that reduced the time taken to gather the necessary information to a single mouse click. The tool was used in four offerings of a third year teacher education unit across 2015 and 2016. Analysis of usage logs indicates that it was used 3,100 separate times to access information on 761 different students, representing 89.5% of the total enrolled students. This usage was spread across 666 days over the two years, representing 91% of the available days during this period. A significant usage level, especially given that most learning analytics dashboards are seldom used to intervene during the teaching of a course (Schmitz et al., 2017). Usage also went beyond responding to discussion forum questions. Since the tool was unintentionally available throughout the entire learning environment (embedded and ubiquitous) unplanned use of the tool developed contributing to improvements in the learner experience. This led to the implication that embedded, ubiquitous, contextual learning analytics encourages greater use and enables emergent practice (Jones et al., 2017). It provides leverage to make the difficult job of teaching a large enrolment, online course easier. However, the implementation of this tool required significant technical knowledge and hence is not easy to master, not accessible, nor easily transferable, Zittrain’s (2008) remaining principles required for a generative platform. The questions now become: How to reduce this difficulty? How to develop a generative learning analytics platform?
To answer this question CASA will draw on a combination of common technologies associated with reproducible research including virtualisation, literate computing (e.g. Jupyter Notebooks), and version control systems (Sinha & Sudhish, 2016) combined with web augmentation (Díaz & Arellano, 2015) and scraping (Glez-Peña, Lourenço, López-Fernández, Reboiro-Jato, & Fdez-Riverola, 2014). Reproducible research technologies enable CASA to draw upon a large and growing collection of tools developed and used by the learning analytics and other research communities. Growth in the importance of reproducible research also means that there is a growing number of university teaching staff familiar with the technology. It also means that there is emerging research literature sharing insights and advice in supporting academics to develop the required skills (e.g. Wilson, 2016). Virtualisation allows CASA to be packed into a single image which allows individuals to easily download, install and execute within their own computing platforms. Web augmentation provides the ability to adapt existing web-based learning environments to embed learning analytics directly into the current common learning context. The combination of these technologies will be used to implement the CASA platform, enabling the broadest possible range of stakeholders to individually and collaboratively design and implement different CASA instances. Such instances can be mixed and matched to suit context-specific requirements and shared amongst a broader community. The following section provides a collection of CASA use case scenarios including explicit links to Zittrain’s (2008) five principal factors of a generative platform.
A particular focus with the CASA platform is to enable individual teachers to adopt CASA instances while minimising the need to engage with institutional support services (accessibility). Consequently a common scenario would be where a teacher (Cara) observes another teacher (Daniel) using a CASA instance. It is obvious to Cara that this specific CASA instance makes a difficult job easier (leverage) and motivates her to trial it. Cara visits the CASA website and downloads and executes a virtual image (the CASA instance) on her computer, assuming she has local administrator rights. Cara configures CASA by visiting a URL to this new CASA instance and stepping through a configuration process that asks for some context specific information (e.g. the URL for Cara’s course sites). Cara’s CASA uses this to download basic clickstream and learner data from the LMS. Finally, Cara downloads the Tampermonkey browser extension and installs the CASA user script to her browser. Now when visiting any of her course websites Cara can access visualisations of basic clickstream data for each student.
To further customise her CASA instance Cara uploads additional data to provide more contextual and pedagogical detail (adaptation). The ability to do this is sign-posted and scaffolded from within the CASA tool (mastery). To expand the learner data Cara sources a CSV file from her institution’s student records system. Once uploaded to CASA all the additional information about each student appears in her CASA and Cara can choose to further hide, reveal, or re-order this information (adaptation). To associate important course events (Corrin et al., 2015) with the clickstream data Cara uses a calendar application to create an iCalendar file with important dates (e.g assignment due dates, weekly lecture times). This is uploaded or connected to CASA and the events are subsequently integrated into the clickstream analytics. At this stage, Cara has used CASA to add embedded, ubiquitous and contextually specific learning analytics about individual students into her course site. At no stage has Cara gained access to new information. CASA has simply made it easier for Cara to access this information, increasing her efficiency (leverage). This positive experience encourages Cara to consider what more is possible.
Cara engages in a discussion with Helen, a local educational designer. The discussion explores the purpose for using learning analytics and how it relates to intended learning outcomes. This leads to questions about exactly how and when Cara is engaging in the learning environment. This leads them to engage in various forms of participatory design with Chuck (a software developer). Chuck demonstrates how the student clickstream notebook form Cara’s existing instance can be copied and modified to visualise staff activity (mastery). Chuck also demonstrates how this new instance can be shared back to the CASA repository and how this process will eventually allow Daniel to choose to adopt this new instance (transferability). These discussions may also reveal insights into other factors such as limitations in Cara’s conceptions and practices of learning and teaching, or institutional factors and limitations (e.g. limited quality or variety of available data).
This paper has described the rationale, origins, theoretical principles, planned technical implementation and possible use cases for CASA. CASA is a generative learning analytics platform which acts as a boundary object. An object that engages diverse stakeholders more effectively in creative acts of making to help make sense of and respond to the diversity and complexity inherent in learning and teaching in contemporary higher education. By allowing both DIW (participatory design) and DIY (end-user development) approaches to the implementation of learning analytics we think CASA can enable the development of embedded, ubiquitous and contextually specific applications of learning analytics, better position teaching as design, and subsequently improve learning experiences and outcomes. As novices to the practice of participatory design we are looking for assistance in examining how insights from participatory design can inform the design and use of CASA. For us, there appear to be three areas of design activity where participatory design can help and a possibility where the addition of generative technology might help strengthen participatory design.
First, the design of the CASA platform itself could benefit from participatory design. A particular challenge to implementation within higher education institutions is that as a generative platform CASA embodies a different mindset. A generative mindset invites open participation and assumes open participation provides significant advantage, especially in terms of achieving contextually appropriate applications. It sees users as partners and co-designers. An institutional mindset tends to see users as the subject of design and due to concerns about privacy, security, and deficit models seek to significantly limit participation in design. Second, the DIW interaction between Cara, Helen and Chuck in the use case section is a potential example of using participatory design and the CASA platform to co-design and co-create contextually specific CASA instances. What methods, tools and techniques from participatory design could help these interactions? Is there benefit in embedding support for some of these within the CASA platform? Lastly, the CASA approach also seeks to enable individual teachers to engage in DIY development. According to Zittrain (2008) the easier we can make it for teachers to develop their own CASA instances (mastery) the more generative the platform will be. What insights from participatory design might help increase CASA’s generative nature? Can CASA be seen as an example of a generative toolkit (Sanders & Strappers, 2014)? Or, does the DIY focus move into the post-design stage (Sanders & Strappers, 2014)? Does it move beyond participatory design? Is the combination of participatory design and generative technology something different and more effective than participatory design alone? If it is separate, then how can the insights generated by DIY making with CASA be fed back into the on-going participatory design of the CASA platform, other CASA instances, and sense-making about the broader institutional context?
Baker, R. (2016). Stupid Tutoring Systems, Intelligent Humans. International Journal of Artificial Intelligence in Education, 26(2), 600-614. https://doi.org/10.1007/s40593-016-0105-0
Beer, C., Tickner, R., & Jones, D. (2014). Three paths for learning analytics and beyond : moving from rhetoric to reality. In B. Hegarty, J. McDonald, & S. Loke (Eds.), Rhetoric and Reality: Critical perspectives on educational technology. Proceedings ascilite Dunedin 2014 (pp. 242-250).
Colvin, C., Dawson, S., Wade, A., & Gašević, D. (2017). Addressing the Challenges of Institutional Adoption. In C. Lang, G. Siemens, A. F. Wise, & D. Gaševic (Eds.), The Handbook of Learning Analytics (pp. 281-289). Alberta, Canada: Society for Learning Analytics Research.
Corrin, L., Kennedy, G., Barba, P. D., Williams, D., Lockyer, L., Dawson, S., & Copeland, S. (2015). Loop : A learning analytics tool to provide teachers with useful data visualisations. In T. Reiners, B. von Konsky, D. Gibson, V. Chang, L.
Irving, & K. Clarke (Eds.), Globally connected, digitally enabled. Proceedings ascilite 2015 (pp. 57-61).
Dede, C. (2008). Theoretical perspectives influencing the use of information technology in teaching and learning. In J. Voogt & G. Knezek (Eds.), International Handbook of Information Technology in Primary and Secondary Education (pp. 43-62). New York: Springer.
Díaz, O., & Arellano, C. (2015). The Augmented Web: Rationales, Opportunities, and Challenges on Browser-Side Transcoding. ACM Trans. Web, 9(2), 8:1-8:30.
Gašević, D., Dawson, S., Rogers, T., & Gasevic, D. (2016). Learning analytics should not promote one size fits all: The effects of instructional conditions in predicating learning success. The Internet and Higher Education, 28, 68-84. https://doi.org/10.1016/j.iheduc.2015.10.002
Glez-Peña, D., Lourenço, A., López-Fernández, H., Reboiro-Jato, M., & Fdez-Riverola, F. (2014). Web scraping technologies in an API world. Briefings in Bioinformatics, 15(5), 788-797. https://doi.org/10.1093/bib/bbt026
Goodyear, P. (2015). Teaching As Design. HERDSA Review of Higher Education, 2, 27-50.
Jones, D. (2011). An Information Systems Design Theory for E-learning (Doctoral thesis, Australian National University, Canberra, Australia). Retrieved from https://openresearch-repository.anu.edu.au/handle/1885/8370
Jones, D., Jones, H., Beer, C., & Lawson, C. (2017, December). Implications and questions for institutional learning analytics implementation arising from teacher DIY learning analytics. Paper presented at the ALASI 2017: Australian Learning Analytics Summer Institute, Brisbane, Australia. Retrieved from http://tiny.cc/ktsdiy
Liu, D. Y.-T., Bartimote-Aufflick, K., Pardo, A., & Bridgeman, A. J. (2017). Data-Driven Personalization of Student Learning Support in Higher Education. In A. Peña-Ayala (Ed.), Learning Analytics: Fundaments, Applications, and Trends (pp. 143-169). Springer International Publishing.
Mishra, P., & Koehler, M. (2006). Technological pedagogical content knowledge: A framework for teacher knowledge. Teachers College Record, 108(6), 1017-1054.
Sanders, E. B.-N., & Stappers, P. J. (2014). Probes, toolkits and prototypes: three approaches to making in codesigning. CoDesign, 10(1), 5-14. https://doi.org/10.1080/15710882.2014.888183
Schmitz, M., Limbeek, E. van, Greller, W., Sloep, P., & Drachsler, H. (2017). Opportunities and Challenges in Using Learning Analytics in Learning Design. In Data Driven Approaches in Digital Education (pp. 209-223). Springer, Cham.
Sinha, R., & Sudhish, P. S. (2016). A principled approach to reproducible research: a comparative review towards scientific integrity in computational research. In 2016 IEEE International Symposium on Ethics in Engineering, Science and Technology (ETHICS) (pp. 1-9).
Suthers, D., & Verbert, K. (2013). Learning analytics as a middle space. In Proceedings of the Third International Conference on Learning Analytics and Knowledge – LAK ’13 (pp. 2-5).
Wilson, G. (2014). Software Carpentry: lessons learned. F1000Research, 3.
Zittrain, J. (2008). The Future of the Internet–And How to Stop It. Yale University Press.
Powered by WordPress & Theme by Anders Norén